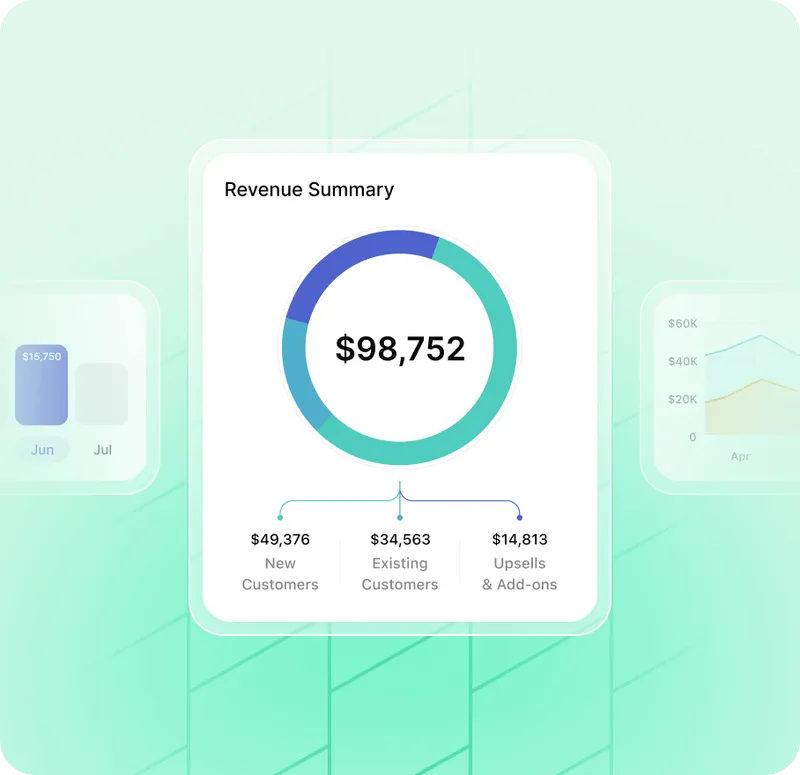
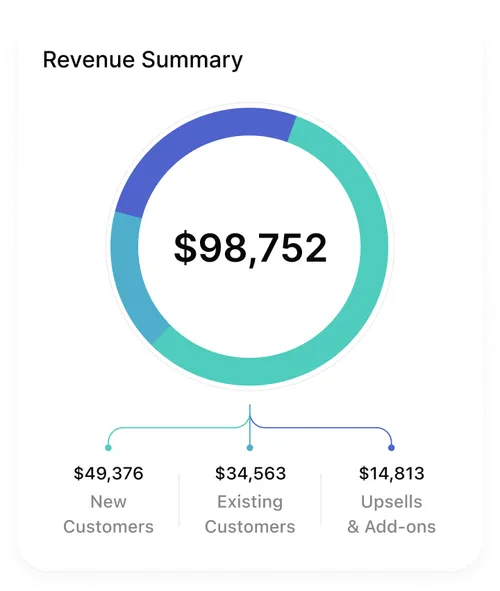
Vision
Make industrial-grade AI and compute as accessible and dependable as utilities, so every builder in Europe can ship real products faster.
We envision a future where industrial-grade AI and computing power are as accessible and reliable as electricity. We are dismantling the barriers of cost and complexity so that every innovator, startup, and enterprise in global market can build and ship world-changing products at the speed of thought.
We deliver more than just AI servers; we deliver certainty. Our mission is to ensure your projects are faster to market, more cost-effective, and entirely future-proof. We achieve this through rapid lead times, fair and direct pricing, and a support team that has your back. By fusing a resilient global supply chain with precise local execution, we give you the freedom to avoid vendor lock-in, safeguard your ROI, and deploy with absolute confidence. Your mission is to lead. Ours is to make sure you have the infrastructure to do it.


Suitable for local integrated hardware and software deployment — private, secure, and production-ready.
 Side
Side
 Front
Front
 Side
Side